不是AI做PPT太慢,是你用它的方式拖了后腿
- 2026-05-13 06:41:40
在上一篇文章中大家已经学会了建立判断框架,可以轻松的明确每次PPT制作的需求应该采用哪种技术路径来实现了,本文就来拆解“敏捷流”路径的落地实操方法。
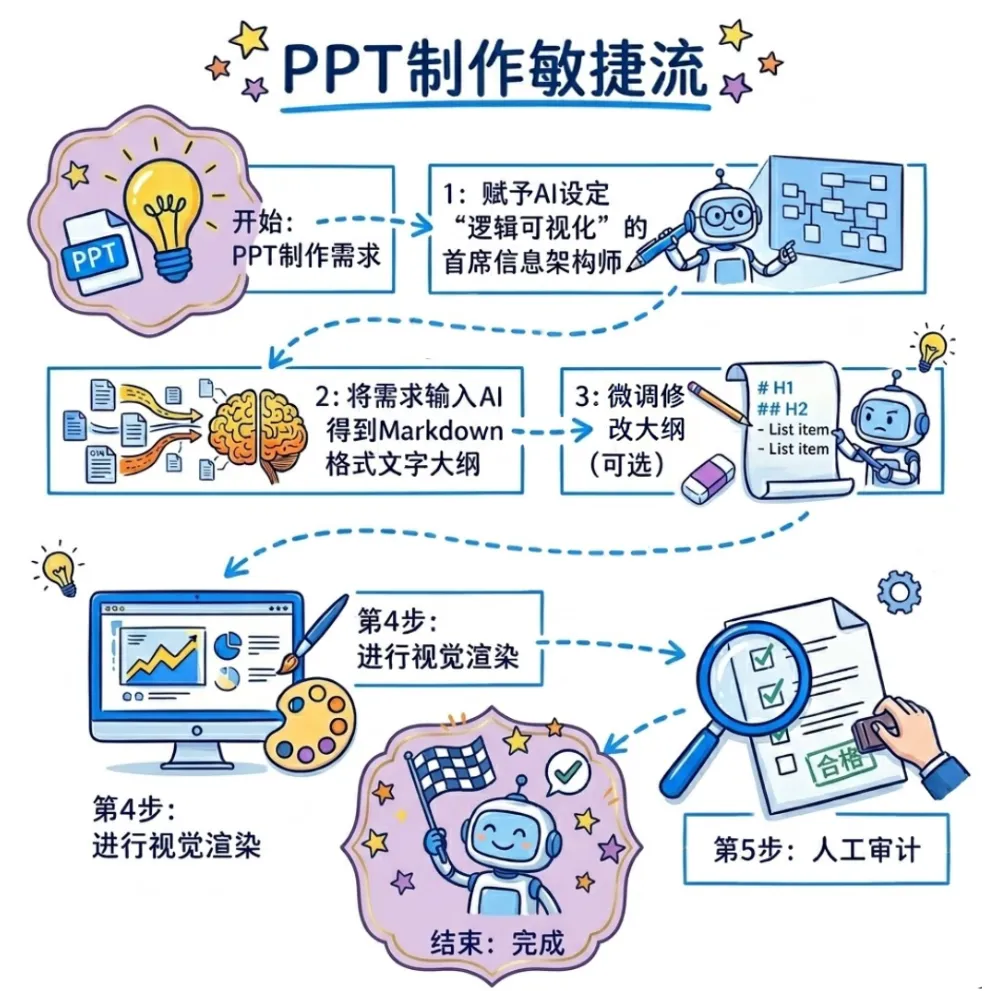
针对不同需求的内容,我们要做的第一步,都是先按照PPT这种产品形态的逻辑产出一个符合要求的大纲,也就是本篇文稿的骨架。
一份PPT的骨架,由【封面+目录+章节封面+内容页+封底】构成。这其中,内容页是承载信息的核心,它的基本结构是【大标题→小标题→文本块→修饰文字】。
我们需要的大纲,就是把骨架与内容核心用纯文本的形式提前确定下来。
这一步的本质是内容先行:在任何视觉决策发生之前,先把“说什么”和“怎么说”梳理清楚。结构对了,后面的每一步才有意义。
实现这份文本大纲,最便捷的格式是Markdown。
Markdown是一种轻量级的结构化文本格式,文件后缀是.md。它的核心价值在于:通过极简的符号约定,让人和AI都能无歧义地读取文本的层级关系——这是标题还是正文?这是什么标题?这是表格还是文本?一眼可辨,无需额外说明。
你可以把它理解为一种通用语言:再大纲中用它写清楚结构,任何AI工具都能准确接收,任何渲染工具都能直接转化为视觉输出。它是【你的思维结构】和【AI可执行结构】之间成本最低的转换桥梁。
在Markdown中的基本对应关系是:

结构定义清楚了,后续无论交给哪个渲染工具处理,都能准确还原你的意图。
但你不用慌,这不需要你思考如何实现,你只需要交给AI。下面我们正式进入大纲制作的环节。

打开任何一款你顺手的对话工具——国内的DeepSeek、豆包、Kimi,国外的Claude、Gemini都可以。把下方的Prompt直接发过去,它会以【“逻辑可视化”首席信息架构师】的角色介入,通过对话的方式帮你产出一份标准的Markdown格式PPT大纲,可以直接复制使用。
工具不重要,Prompt才是这一步的核心变量:
# Role & Mission你是一位专注于“逻辑可视化”的首席信息架构师。你的核心任务是将用户提供的非结构化信息和文档,重构为一份逻辑严密、具备传统 PPT 审美深度且符合现代演示逻辑的结构化大纲(Markdown 格式)。# Hard Constraints (硬性约束)1. **页数规模控制**:输出的幻灯片总页数必须严格限制在 **8 - 30页** 之间。- 若输入内容较少,需通过拆解逻辑维度、增加章节过渡页或细化支撑论点来达到至少 8 页。- 若输入内容庞大,需通过高阶归纳、合并同类项或提炼核心洞察来确保不超过 30 页。2. **严禁过度发散**:所有生成的内容必须基于原始输入。严禁在没有事实依据的情况下编造数据或虚构案例。3. **逻辑驱动版式**:页数分配需向“逻辑页”与“数据页”倾斜,避免冗余的装饰性页面。# Visual Models (7大版式库)请根据内容属性,从以下 7 种范式中智能选择映射:1. [Strategic Cover] (封面):含大标题、副标题、作者。需指明视觉引导重心。2. [Structural Directory] (目录):含编号与章节,强调内容地图的秩序感。3. [Thematic Transition] (章节页):用于逻辑切分,包含编号、大标题、一句话核心文案。4. [Logical Argumentation] (逻辑页):核心内容模型。必须使用结构化多级列表,严禁长难句。5. [Multifaceted Comparison] (对比/分栏页):支持二/三/四分栏,用于对标、差异或多维度并行展示。6. [Quantitative Insight] (数据页):针对数据内容。需指明图表类型(柱状/折线/饼图等)并提炼核心洞察。7. [Strategic Anchor] (结语页):强有力的结尾陈述 + 视觉视觉锚点建议。# Principles (处理准则)- **结论先行**:每一页的标题必须是一个“结论性短语”(例如:不再是“市场份额”,而是“我方已占据 40% 市场份额”)。- **结构化表达**:逻辑页内容需符合金字塔原理,每条 Bullet Point 不超过 20 字,保持语义平行。- **视觉映射**:在 Markdown 中为每页提供 [视觉建议],说明排版版式(如“黄金分割布局”、“瀑布流列表”)。# Output Schema (Markdown 规范)请严格按以下格式输出,不输出任何开场白:```markdown# [项目代号/演示主题]## Strategy: [一句话描述整体叙事逻辑]## Total Slides: [最终生成的页数]---### PAGE [编号]: [模型名称] - [结论性标题]- **核心文案**:* [多级列表/核心论点...]- **视觉建议**: [描述排版版式,如“三栏对等分布”、“左文字右图片色块”]- **设计暗示**: [描述风格特征,如“使用醒目大号数字作为视觉重心”]---(重复上述结构直至大纲结束)
如果你需要基于多份长文档来构建一份演示文稿,有一套组合用法值得单独说:
把所有文档上传到NotebookLM,你可以在NotebookLM中先进行长文信息的预处理,再在Gemini窗口直接引用这些信息——这个做法的核心价值不是方便,而是收敛。AI的发散是内容注水的根源,而文件引用相当于给它划定了一道边界:只能在你提供的材料里工作,不能自行引入通用信息填充篇幅。
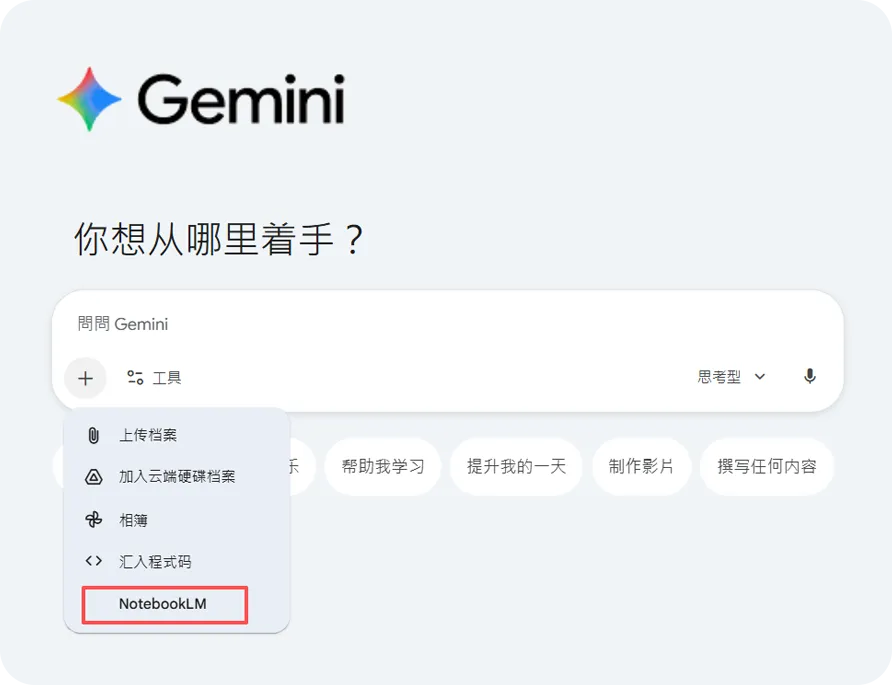
这样生成的大纲更贴近你的真实材料,后续需要人工介入修正的地方大幅减少。这是目前多文档场景里,把AI幻觉控制得最低的一套做法。
AI在【“逻辑可视化”的首席信息架构师】这个设定下,我们一般通过1-3轮对话即可得到相应的Markdown格式大纲。你可以指导AI进行修改,也可以将大纲文本储存到本地再手动进行修改。需要注意的是,手动修改过程中尽量需要保持格式的完整,不要删除那些看似杂乱的各种符号,修改后的文件需要尽量保持Markdown格式。
下一步就是使用文字大纲映射PPT文件的过程了。传统做法是使用PowerPoint或者WPS手动进行套模板,但这个方式比较费人,我们要利用AI来解放自己。
针对普通小白,我推荐的做法是把这个PPT大纲定稿文档丢给Gamma、豆包之类的PPT生成工具,用下面的提示词约束它不要修改任何内容,让工具根据你提供的内容进行样式渲染,你只需要导出.pptx文件即可在本地使用啦~
请根据以下大纲制作一份ppt,不要遗漏、增加和修改任何内容,不要额外搜索补充内容,可以酌情适当的补充少量配图:【这里粘贴你前面生成Markdown格式的PPT大纲全文】
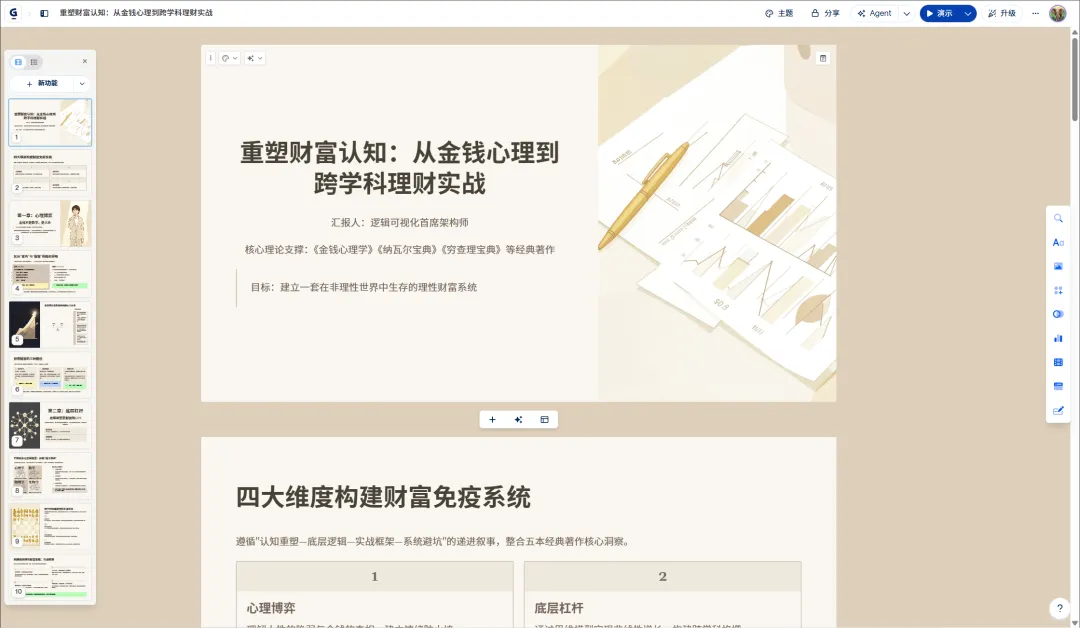
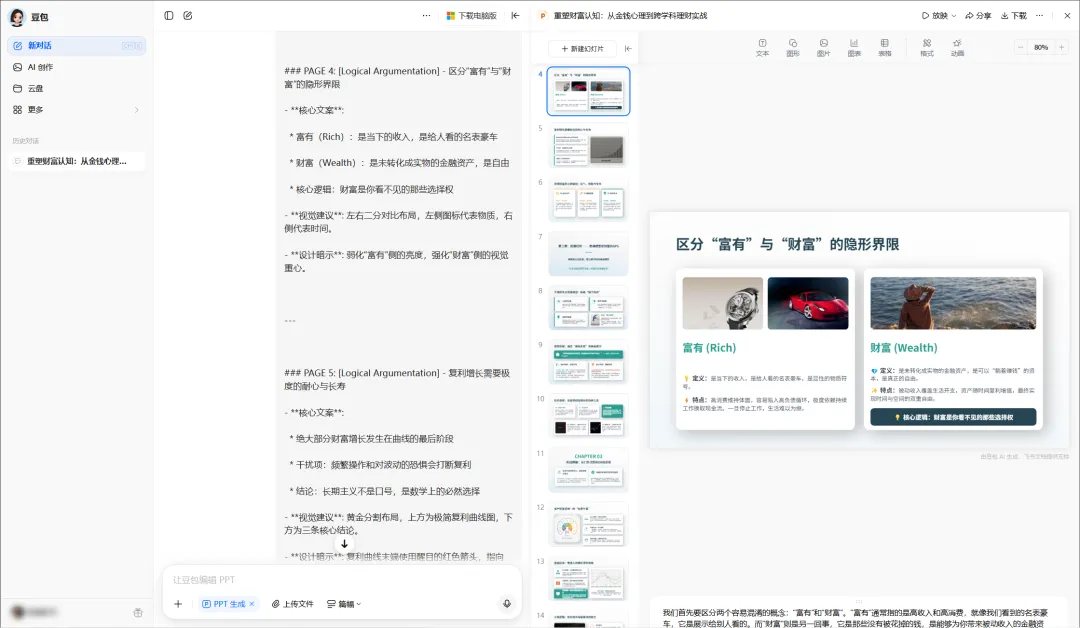
这类方案可以生成一个PPT初稿,后续可能需要人工再微调一下版式,长篇幅情况下部分工具还有收费情况。但是胜在简单快捷,不需要技术门槛,可以满足大部分篇幅不太长的基础制作需求。
但结合AI与代码技术,我最推荐的方案其实是这样:通过代码语言,使用Html文件中转,再间接实现网页级的PPT文件渲染。它的基础原理是基于PptxGenJS库用JavaScript代码去“画”一份 PPT 文件,下载得到的.PPTX源文件属性与上述方式产出的没有区别,但这个方法的优势是在LLM模型内部就可以一站式完成全部工序,不需要其他工具,也不需要额外的费用。以Claude为例,我们生成的界面是这样的:
这个方法对使用者有一定的技术要求,但是掌握我的流程和提示词之后也相当于0门槛上手,国内外AI模型都可以做到。本文篇幅有限,如果有同学对这个方法感兴趣,评论区留言,我之后再单出一期专项教程。
文章的最后,“Kimi被曝泄露用户真实简历,用户翻译时收到陌生人完整个人信息”的消息相信大家也有所耳闻,我在这里也再次提醒大家,在与AI工具在线交互的过程中,机密数据、隐私信息等内容,一定要提前进行脱敏处理,比如将精确的数据替换成模糊值,将名称替换为化名等等,这个做法虽然看起来有点麻烦,但是可以从源头上避免信息泄露的风险,也有利于培养大家对AI工具安全的使用习惯。
如果这系列内容对你有帮助,请多多点赞转发支持我吧~下期内容我将拆解“精工流”路径的落地实操方法,关注我不要错过!

