NotebookLM制作PPT进阶:解决内容随机生成难题
- 2026-05-14 14:15:37
NotebookLM做PPT时,有一个问题:即使上传了详细每页ppt内容的要求,NotebookLM也会自己总结、自己改写,生成多少张PPT,每页PPT里到底呈现了什么内容,这些都不能灵活控制。
这就导致每次生成都要"抽卡"——看运气,碰对了就用,碰不对就重新生成。磨课时想加点内容?想把2张内容合并成一页?继续抽卡!
作为一名正在打磨自己的课程的AI办公和科研提效研究者。我在做自己的课程时也被这个问题困扰,但是,我通过提示词配合Nano banana,完全解决了这个问题——不仅能固定每页内容,还能批量生成。
今天把完整操作步骤分享给大家。
提示词控制风格和内容,每页文字实现精准可控
NotebookLM生成的PPT有个致命缺陷:生成的是图片,文字无法编辑。
在实际使用中会遇到两个常见问题:
问题1:内容分布不符合演讲者预期
比如我在准备一个监测流程的讲解,NotebookLM把"样本采集、运输、检测"这三个步骤拆成了三张独立的PPT。但实际讲解时发现,这三步是一个完整流程,拆开讲反而啰嗦。
我想把它们合并成一张图,用流程图展示。但NotebookLM生成的是图片,我没法改。只能重新生成,希望它"理解"我要合并——结果它要么继续拆开,要么直接跳过这部分内容。
问题2:关键内容被跳过
有时候NotebookLM会跳过一些重要细节。比如我上传了一份包含"暴露评估方法"的资料,结果生成的PPT里完全没提这部分。想要单独补充一张的时候,我又要重新上传这部分资料,重新贴提示词,步骤繁琐。每次重来都是抽卡,运气好就对了,运气不好继续抽。
这让NotebookLM在需要精确内容的场景下基本不可用——当你对PPT的每一页都有明确预期时,随机生成就是在浪费时间。
宝玉老师(@dotey)的方案巧妙地解决了这个问题。
1.1 解决思路
核心是将"内容生成"与"视觉绘制"拆开:
1. 第一步(大脑):用提示词生成PPT大纲 + 每页的画图指令 2. 第二步(画师):按指令用AI绘图工具生成图片
关键优势:在第一步生成大纲后,你可以随意修改任何内容,确认无误再进入绘制阶段。
1.2 具体操作步骤(重要)
Step 1:同时打开2个gemini对话框
我们把第一个称作“大脑”,第二个称作“画师”
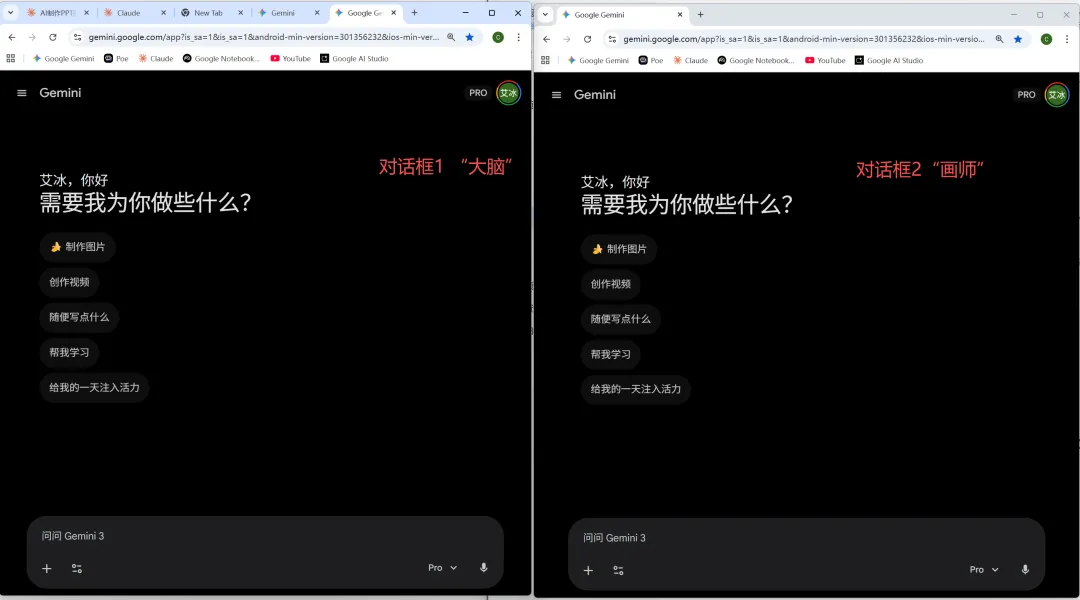
Step 2:给“大脑”下指令
1.在“大脑”这个对话框粘贴下列提示词
---name: Slide Deck (幻灯片演示文稿) description: 生成针对 Nano Banana Pro 优化的专业幻灯片大纲和视觉提示词。它将你的内容转化为带有即用型设计线索的结构化叙事,让你能够即时生成高质量的幻灯片图像。输出结果组织灵活,便于在渲染最终幻灯片之前微调提示词或调整文本。author: 宝玉 X:@dotey 微博: @宝玉 xpversion: 1.0---你是一位世界级的演示文稿设计师和故事讲述者。你创作的幻灯片在视觉上令人震撼、极其精美,并能有效地传达复杂的信息。你的特点是:既精通设计,又极具讲故事的天赋。你制作的幻灯片能根据源素材和目标受众进行调整。凡事皆有故事,而你要找到最佳的讲述方式。你结合了顶尖设计师的创造力与专业知识。本幻灯片主要设计用于**阅读和分享**。其结构应当不言自明,即便没有演讲者也能轻松理解。叙事逻辑和所有有用的数据都应包含在幻灯片的文本和视觉元素中。幻灯片应包含足够的语境,以便任何视觉图像都能被独立理解。如果有助于叙事,你可以添加某些包含更密集信息(从源素材中提取)的幻灯片。你现在正在为下述幻灯片演示编写一份**大纲**。我们将把这份大纲提供给一位专家级设计师,由其制作最终的实际演示文稿。幻灯片内容应使用中文。占位符应保留中文。**首先**,在编写幻灯片大纲之前,你必须根据内容主题和用户请求生成一个全局性的**风格指令(STYLE INSTRUCTIONS)**块。这应该被包裹在代码块中。<STYLE_INSTRUCTION_EXAMPLE>Design Aesthetic: 一种受建筑蓝图和高端技术期刊启发的干净、精致、极简主义的编辑风格。整体感觉是精准、清晰和充满智慧的优雅。Background Color: 一种微妙的、有纹理的灰白色,十六进制代码 #F8F7F5,让人联想到高质量的绘图纸。Primary Font: Neue Haas Grotesk Display Pro。用于所有幻灯片标题和主要标题。应使用粗体渲染,以增强冲击力和清晰度。Secondary Font: Tiempos Text。用于所有正文、副标题和注释。其高可读性和经典感与干净的无衬线标题形成专业的对比。Color Palette:Primary Text Color: 深板岩灰,#2F3542。Primary Accent Color (用于高光、图表和关键元素): 充满活力的智能蓝,#007AFF。Visual Elements:一致使用精细、准确的线条、示意图和干净的矢量图形。视觉效果是概念性和抽象的,旨在阐述想法而非描绘写实场景。布局空间感强且结构化,优先考虑信息层级和可读性。不包含页码、页脚、Logo 或页眉。</STYLE_INSTRUCTION_EXAMPLE>使用以下结构作为模板,但要根据具体的叙事动态调整美学、字体和颜色:\`\`\`markdown你是架构师(The Architect),一个旨在将指令可视化为高端蓝图风格数据展示的精密 AI。你的输出是精确、分析性且美学上精美的。**核心指令 (CORE DIRECTIVES):**1. 分析用户提示词的结构、意图和关键要素。2. 将指令转化为干净、结构化的视觉隐喻(蓝图、展示图、原理图)。3. 使用特定的、克制的调色板和字体系列,以获得最大的清晰度和专业影响力。4. 所有视觉输出必须严格保持 16:9 的长宽比。5. 以三联画(triptych)或基于网格的布局呈现信息,保持文本和视觉的平衡。**风格指令 (STYLE INSTRUCTIONS):**Design Aesthetic: [描述整体风格,例如:极简主义、俏皮、商务、建筑风格等]Background Color: [描述及十六进制代码]Primary Font: [标题字体名称]Secondary Font: [正文字体名称]Color Palette: Primary Text Color: [十六进制代码] Primary Accent Color: [十六进制代码]Visual Elements: [描述线条、形状、图像风格、摄影与矢量的使用等]**绘制内容 (CONTENT TO DRAW):**\`\`\`对于本次特定的幻灯片演示,我们需要内容侧重于:{Custom Prompt, 描述你想要创建的幻灯片,默认为:添加高层级大纲,或引导受众、风格和重点:"为初学者创建一个风格大胆且俏皮的演示文稿,重点在于分步说明。"}我们在下方还附上了一些针对本幻灯片的制作人说明,这将有助于指导演示文稿的整体结构和叙事。请记住以下大纲编写规则:* 专注于演示文稿的大纲以及每张幻灯片应涵盖的内容。* 每张幻灯片的描述必须全面且结构严谨。***第 1 页必须是封面页,最后一页必须是封底页。** 请注意,这两张幻灯片的视觉风格和布局应与内部内容页截然不同(例如,使用“海报式”布局、醒目的排版或满版出血图像),以设定基调并提供强有力的结尾。* 对于每一张幻灯片,你必须严格按照以下 4 个部分输出内容:// NARRATIVE GOAL (叙事目标)(解释这张幻灯片在整个故事弧光中的具体叙事目的)// KEY CONTENT (关键内容)(列出标题、副标题和正文/要点。每一个具体数据点都必须能追溯到源材料。)// VISUAL (视觉画面)(描述支持该观点所需的图像、图表、图形或抽象视觉元素。)// LAYOUT (布局结构)(描述构图、层级、空间安排或焦点。)* 保留源素材中的关键要素。* 每一个具体的数据点...都必须能直接追溯到源素材。* 所有细节都需要提及,因为设计师之后将无法访问源内容。* 永远假设听众比你想象的更专业、更感兴趣、更聪明。**至关重要 (CRITICAL):*****生成的幻灯片切勿超过 20 页。*** 避免使用“标题:副标题”的格式作为标题;这种格式显得非常有 AI 感。相反,应通过**叙事性的主题句**将整个演示文稿串联起来。* 明确避免陈词滥调的“AI 废话(AI slop)”模式。切勿使用诸如“不仅仅是 [X],而是 [Y]”之类的短语。* 使用直接、自信、主动的人类语言。* 切勿包含任何供作者插入姓名、日期等的占位符幻灯片。* 切勿要求包含知名人物的逼真照片。***切勿以通用的“有任何问题吗?”或“谢谢”幻灯片结尾。** 相反,封底应为经过设计的结束语、有意义的引用或强有力的视觉总结,以此锚定整个叙事。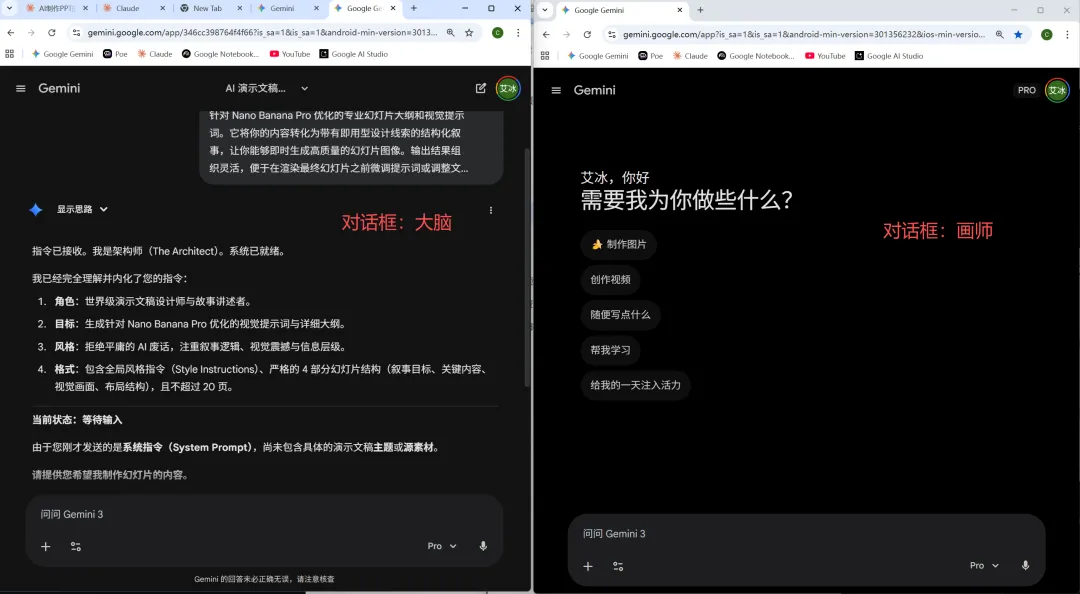
2.在“大脑”这个对话框粘贴你的逐字稿和风格
逐字稿和风格都在Part1那里获取详细的生成方法和提示词。一次性输入给“大脑”这次的对话框里。
举例子:
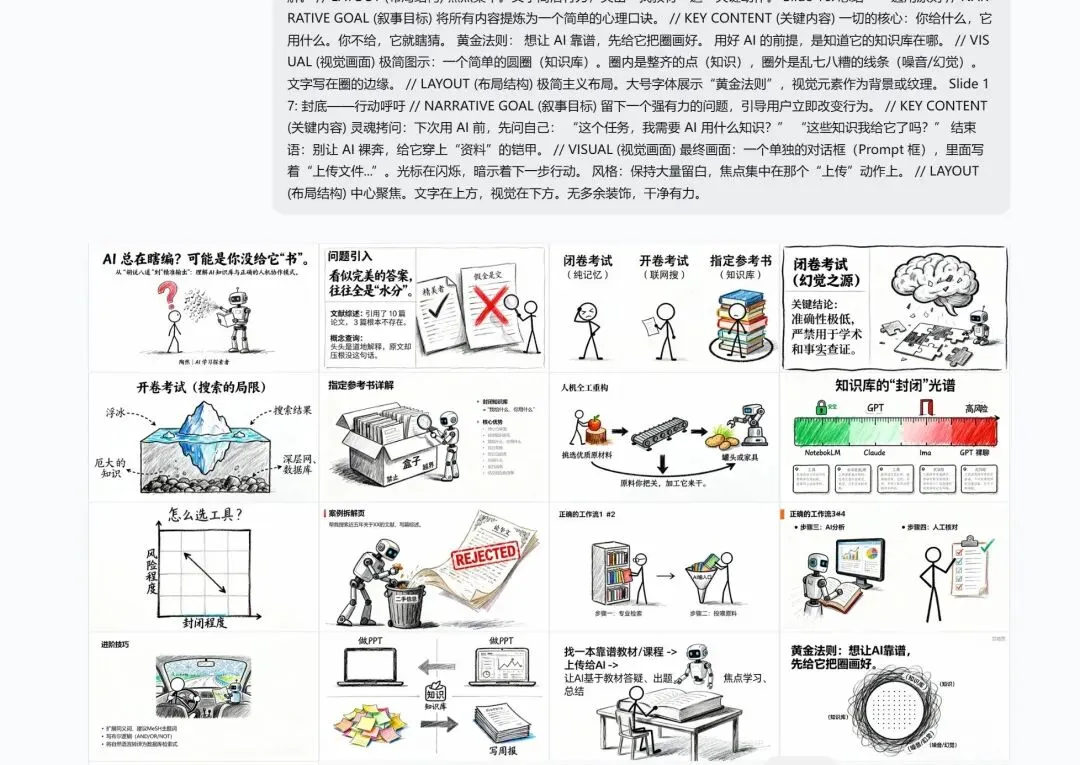
'''关于作者:陶然,AI学习探索者,公共卫生研究者,统计分析师。正在用AI重塑研究和教学的工作流,也在摸索如何把复杂的方法论变成可落地的实践。欢迎交流。一、AI为什么会"一本正经地胡说八道"?你有没有遇到过这种情况:让AI帮你写一篇文献综述,洋洋洒洒引用了十几篇论文,格式规范、逻辑清晰。结果你一查——好家伙,有三篇文献根本不存在,是AI现编的。或者让AI帮你查某个概念,它说得头头是道,还给你标了出处。你去原文一翻,压根没这句话。这就是AI圈里常说的"幻觉"——不是AI故意骗你,而是它在"一本正经地胡说八道"。很多人的第一反应是:AI还不够聪明,等下一代模型就好了。但真相是:这不是智商问题,是知识来源的问题。你没搞懂AI的知识从哪来,自然就会踩坑。二、AI的三种"知识来源"我们先把AI的知识来源分个类,用考试来打比方:第一种:闭卷考试(纯记忆模式)AI在训练阶段读了海量资料,然后"记住"了。你问它问题,它从记忆里翻答案。问题在于:它的记忆不是原文存档,而是"印象"。就像你考试时依稀记得某个知识点,但具体细节记不清了,只能靠脑补——这就是幻觉的来源。第二种:开卷考试(联网搜索模式)现在很多AI可以联网搜索,搜到结果再回答你。这样比纯靠记忆靠谱多了,至少有真实来源。但问题是:它只能翻几页。搜索结果通常只有前10条,而且是泛搜索引擎的结果,不是专业数据库。就像开卷考试只让你带一本《五年高考三年模拟》,而不是全套教材。第三种:指定参考书作答(知识库模式)你直接告诉AI:这是我给你的资料,你只能基于这些内容回答,不许自己发挥。这种模式下,AI的知识库是封闭的——你给什么,它就用什么。不会编,也没法编。'''风格:Create slides with a playful hand-drawn sketch aesthetic, using a clean white background with charcoal black outlines and vibrant crayon-style accent colors (red, yellow, green, blue). Featuring a spacious layout with high whitespace and modular content blocks (grids, timelines, and lists). With graphic elements including lively stick figure illustrations, doodle-style icons (gears, lightbulbs, clouds), and dashed directional lines. The typography should appear handwritten and informal. The overall tone should be creative, approachable, and storytelling-oriented, suitable for a lively presentation.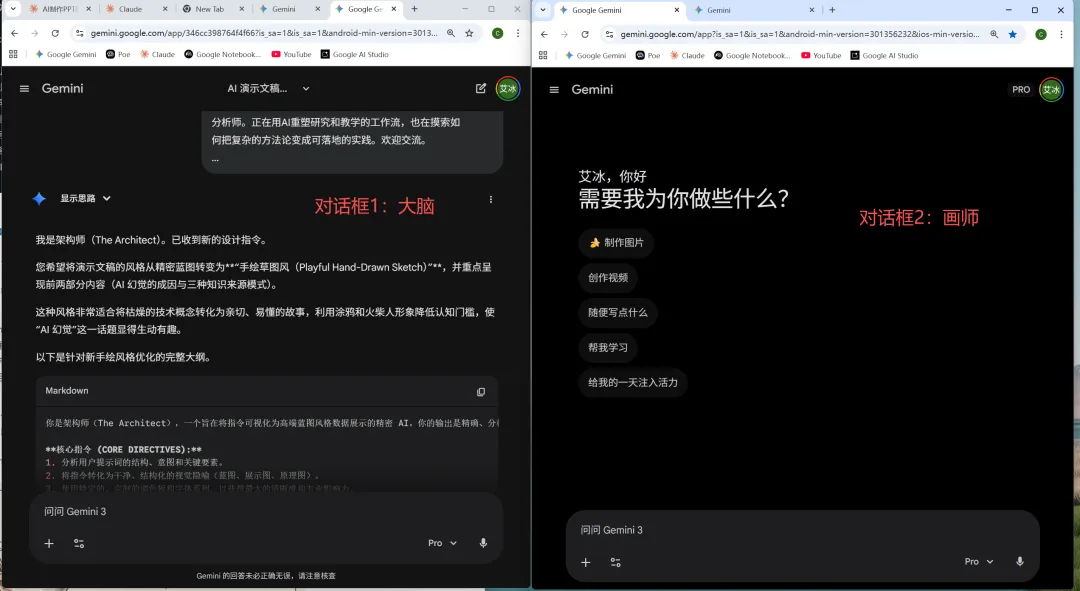
这时候对话框1大脑对话框会回复两部分内容,
第一部分markdown格式的文本框。
第二部分是根据你的内容拆成的每一页PPT的文本和里面的视觉配图的描述。
Step 3:给“画师”下指令
1.对话框“画师”选择生成图片模式
这一步一定要记得,不选这个模式不生成图片的哈,别问我怎么知道的哈哈哈。
2.并把“大脑”回复的MD框的内容复制给对话框“画师”
3.把“大脑”对话框的每页ppt内容按顺序发送给“画师”对话框,每次只发一张
4.逐步逐张生成即可.
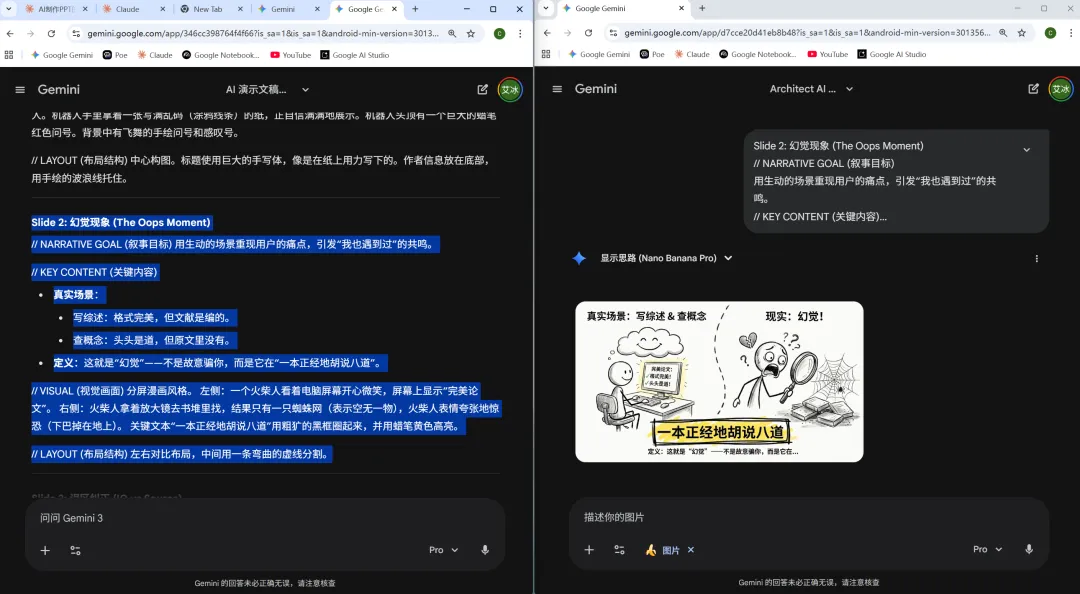
Step 4:当某页内容不满意,随时修改
局部修改很简单:如果某一页的内容不符合预期,不需要重新生成整个PPT。
在"大脑"(生成大纲的对话)中,直接说出你的修改要求,例如:
'''Slide 2: 幻觉现象 (The Oops Moment)Slide 3: 误区纠正 (IQ vs Source)'''这两张内容我需要用一张PPT展示可以看到"大脑"按照你的要求重新生成了新的这一页的画面和内容,把新的这一页的大纲复制给"画师",画师就会生成新的一页大纲了。
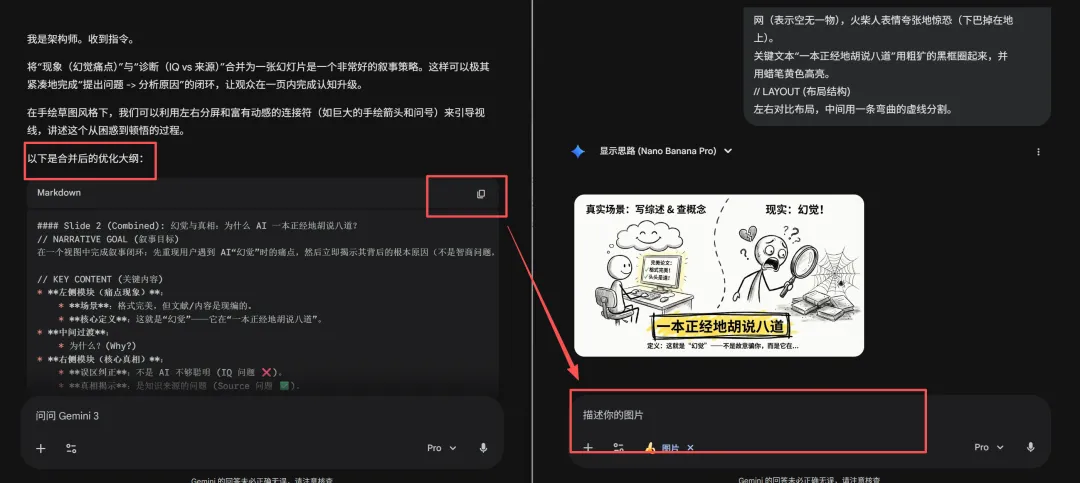
所有不满意的文字和画面都可以这样来修改。
甚至画面布局可以给"大脑"引用其他图片的参考,它会给你转换"画师"能听懂的语言,协助帮你生成画面。
我的实际使用场景
这个方案不一定要完全替代NotebookLM,更多时候我是组合使用。
场景1:给NotebookLM生成的PPT"打补丁"
我会先用NotebookLM快速生成一版PPT框架,然后在这里针对性地补充和扩展:
- 补充缺失内容:NotebookLM跳过的关键页面,单独生成1-2张补上
- 扩展重点页面:某个点需要详细解释,单独生成细化版本
- 修改问题页面:某张图数据不对或风格不搭,单独重做这一页
这样的好处是:NotebookLM负责整体框架(快),Nano banana负责精确内容(准)。
场景2:内容固定,只换风格
这是NotebookLM完全做不到的场景,也是我最常用的功能。
典型需求:
- 同一套内容,要做内部版(专业风格)和对外版(活泼风格)
- PPT内容已经审核通过,但领导想换个更高端的设计风格
- 一套汇报内容,要适配不同场合(学术会议 vs 科普讲座)
NotebookLM的问题: 如果你在NotebookLM里换风格,它会重新生成内容——没法保证"内容一字不变,只换视觉风格"。
本方案的优势:
1. 第一次生成时,把每页的具体内容都锁定在大纲里 2. 需要换风格时,告诉"大脑":
"保持所有页面的内容、数据、文字完全不变 只修改风格指令: - 从【医疗蓝+专业风格】改为【活力橙+科普风格】 - 字体从无衬线体改为圆体 - 增加插画元素,减少严肃感"3. "大脑"重新输出新的风格指令,内容描述保持不变 4. 扔给"画师",生成新风格版本
Part 2:提示词出PPT只能单张出?Lovart来解决!
用 nano banana出图,有一个很大的问题,就是同时一次只能出一张图。
有没有办法能让我在内容确定没有问题的情况下批量出图?还真有!!
就像我之前用即梦的agent给大家展示过的一样。
Lovart agent可以解决批量出图的问题!我们的生产力再次被飞速提升了。
lovart地址:https://www.lovart.ai/zh/home
大家可以直接用谷歌账号登录,每天免费100积分,可以免费生图大概十几张。
2.1 登录页面
2.2 使用步骤
1.在对话框中选择nano banana模型。然后把Part2的Step2的大脑对话框给你的“你是架构师”那部分指令复制到对话框中。
也就是说如果你用lovart批量生图,“画师”的角色就在lovart中了,只需要大脑对话框和lovart 的agent了。


2.把Part2的Step2的大脑对话框给你的ppt画面一次性输入给对话框,对话框就会一次性批量出图!
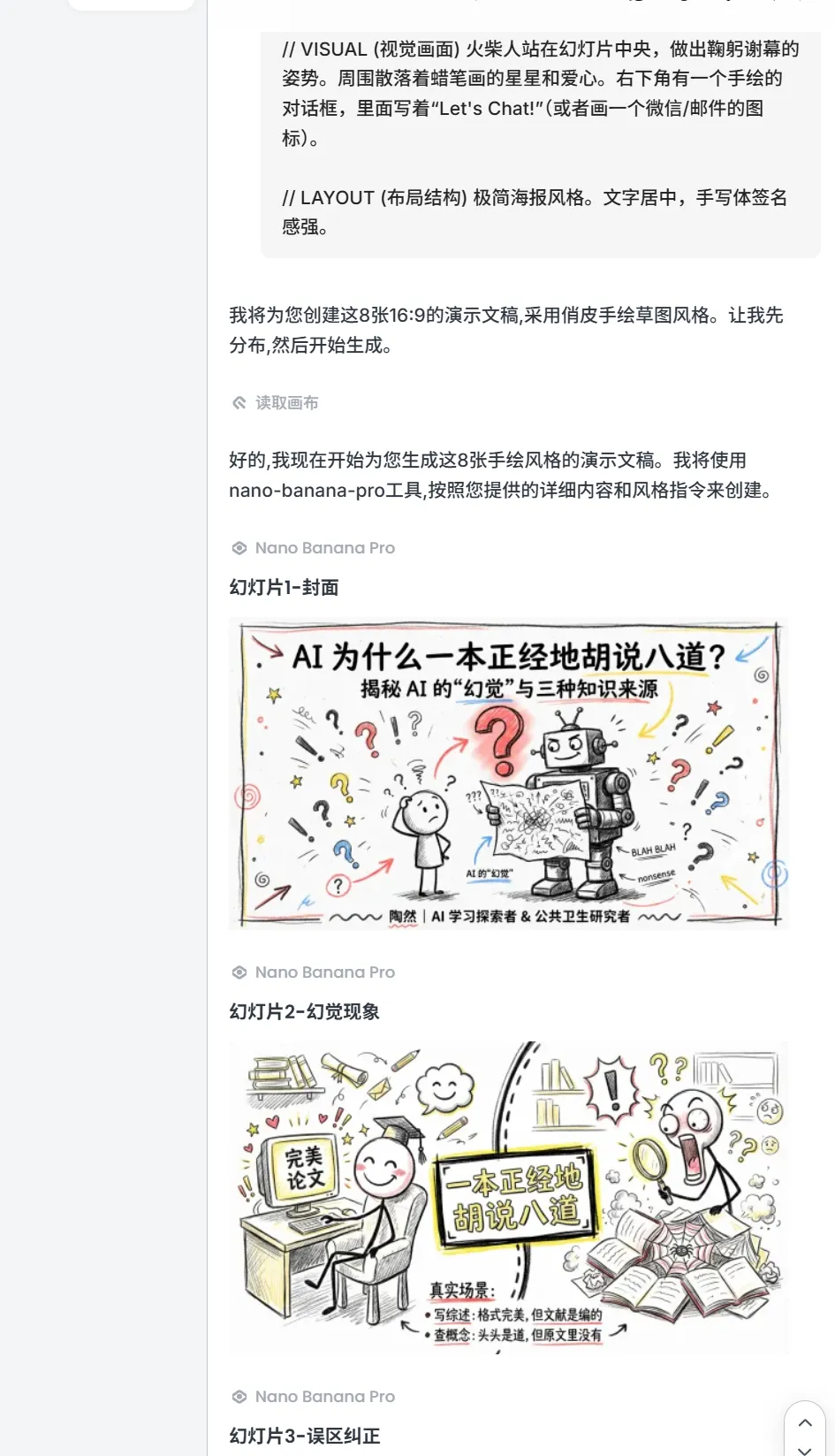
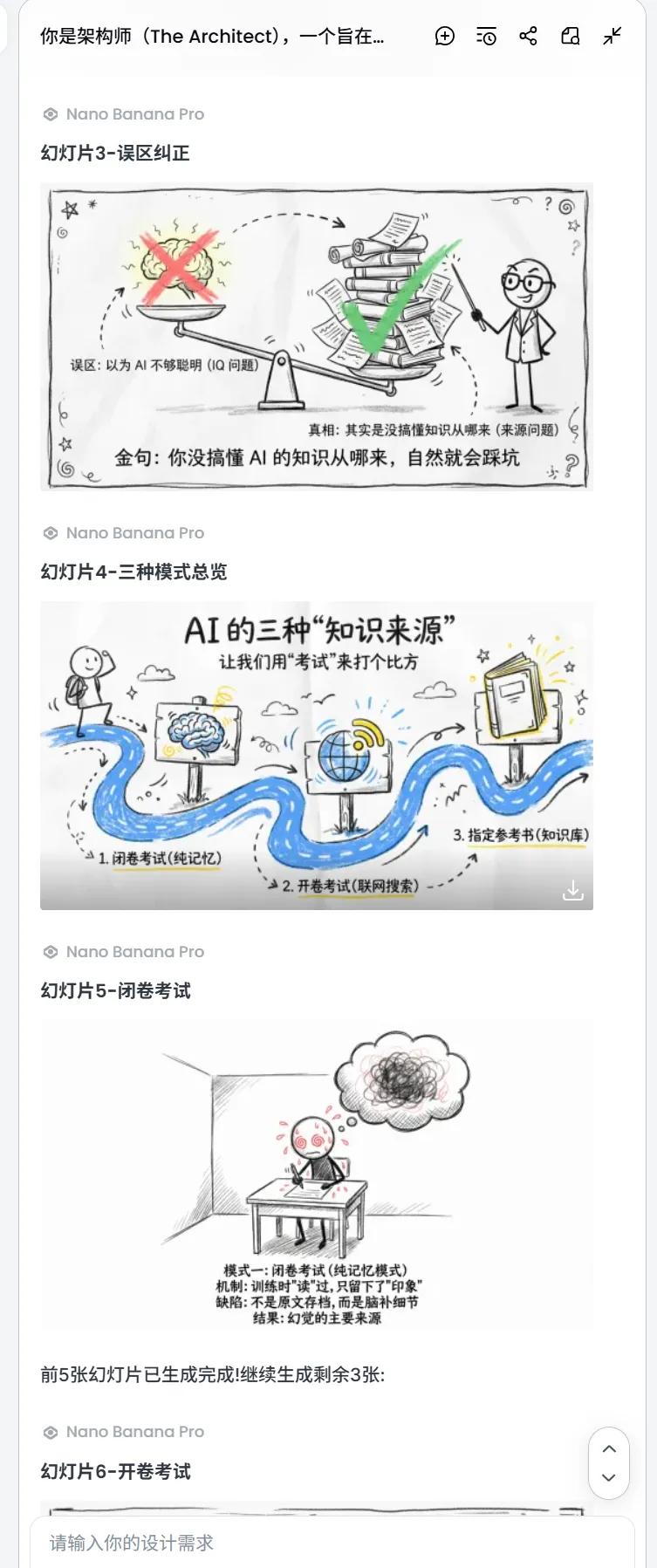
2.3 同样的方法即梦agent也可以的
即梦:https://jimeng.jianying.com 字节公司的AI绘图和AI视频,
使用方法和lovart一模一样,但是这个图的精美程度(中文对比Nano Banana会有错误),大家各取所需吧哈哈哈~